product
How We're Building the World's First Media Database powered by AI-agents
A journalist database that's always fresh—because AI agents can enrich live
View as Markdown
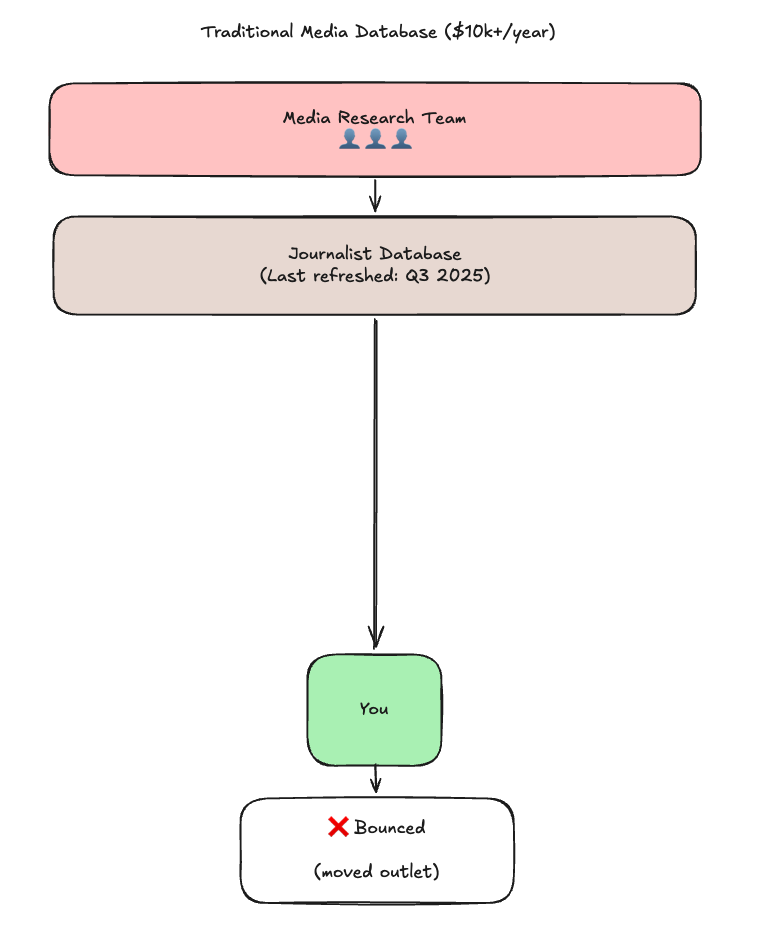
Traditional media databases—Muck Rack, Cision, and others—employ teams of researchers to manually update journalist records. They check publications, scrape LinkedIn, send verification emails. It's expensive, slow, and broken.
The fundamentally flaw: humans can't scale. There are more than 800,000+ working journalists. No team of researchers can keep up with job changes, beat shifts, and email churn.
Our Approach: AI Agents That Never Sleep
We built something different: a database that's always fresh because AI agents can enrich data live.
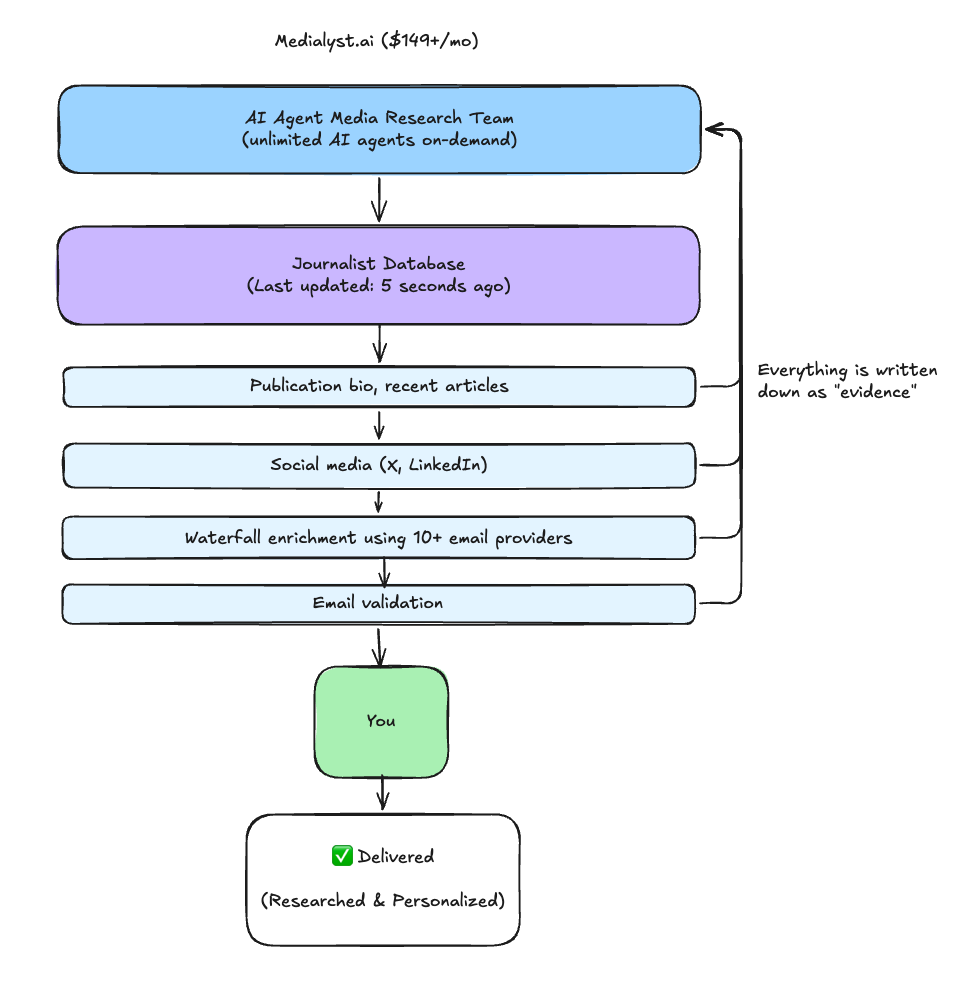
Stale record? Missing data? No problem—AI agents research, validate, and return fresh data in seconds. And everything they learn gets written back, making the database smarter for next time.
What Powers Live Enrichment
When data is stale or missing, our enrichment layer pulls from multiple sources simultaneously, cross-references them, and writes everything back to the database:
Email Providers (Waterfall)
- 10+ providers: Hunter, Apollo, Snov.io, Prospeo, Lusha, Clearbit, RocketReach, Findymail, Dropcontact, and more
- Strategy: Waterfall through providers until we find a hit
- Validation: Real-time deliverability check before returning
Social Platforms
- X: Handle, bio, outlet mentions, recent posts, follower count
- LinkedIn: Current role, company, headline, location
- Used for: Cross-referencing, beat detection, catching job changes
Publication Data
- Author page extraction (bylines, bio, contact info)
- Publication classification (editorial vs brand content)
- Traffic & authority metrics
- Recent article analysis for beat detection
The Flywheel: Every source that returns data gets cross-referenced, validated, and written back. Your lookup today makes the next lookup instant.
How It Works
Fast When Accurate, Thorough When Needed
Most lookups return instantly—we've already validated that journalist recently.
But when data is stale or missing, we take the time to get it right. AI agents research live, validate the email, and return fresh results. It takes a few seconds longer, but you get data you can trust.
You're never stuck with "this was accurate 6 months ago, good luck." You always get current, validated information.
It Gets Smarter Every Time You Use It
Here's what makes this genuinely different from any media database before: the system improves at a rate proportional to how much it runs, not how much we work on it.
Every lookup improves the database. Every failure teaches something:
- Job changes caught in days, not months — Byline monitoring spots when journalists move outlets. When an agent sees a byline pattern shift, it logs it, investigates, and updates the record.
- Beats update automatically — Coverage patterns shift? We notice. Article analysis runs continuously, adjusting beat classifications as journalists evolve.
- Emails that actually work — Multiple sources, validated before you send. Bounces get logged and trigger re-enrichment.
- Proactive refresh — Stale profiles get updated before you even search. Agents analyze their own failure logs to spot systematic gaps.
The more people use it, the fresher it stays. Your lookup today makes someone else's lookup tomorrow more accurate.
Traditional databases can't do this. Their feedback loop requires:
- Users complaining about bad data
- Support tickets reaching product team
- Engineers investigating and shipping fixes
- Weeks to months per improvement cycle
Our feedback loop is minutes. Agents spot patterns in their own failures, log them, analyze them, and either fix them autonomously or surface them for review.
The implication is profound: the database becomes better than anything a human team could maintain, because it's learning from thousands of micro-failures that would be invisible to humans reviewing aggregate metrics.
Every bounced email, every 404, every "journalist not found" makes the system smarter. The more it runs, the fewer failures it generates. The fewer failures it generates, the more accurate it becomes. The more accurate it becomes, the more people use it. The more people use it, the more it learns.
This is the flywheel traditional databases can't compete with.
The Accuracy Curve
Traditional databases are most accurate the day after a refresh. Then they decay until the next refresh.
We're building the opposite: a system that gets more accurate over time.
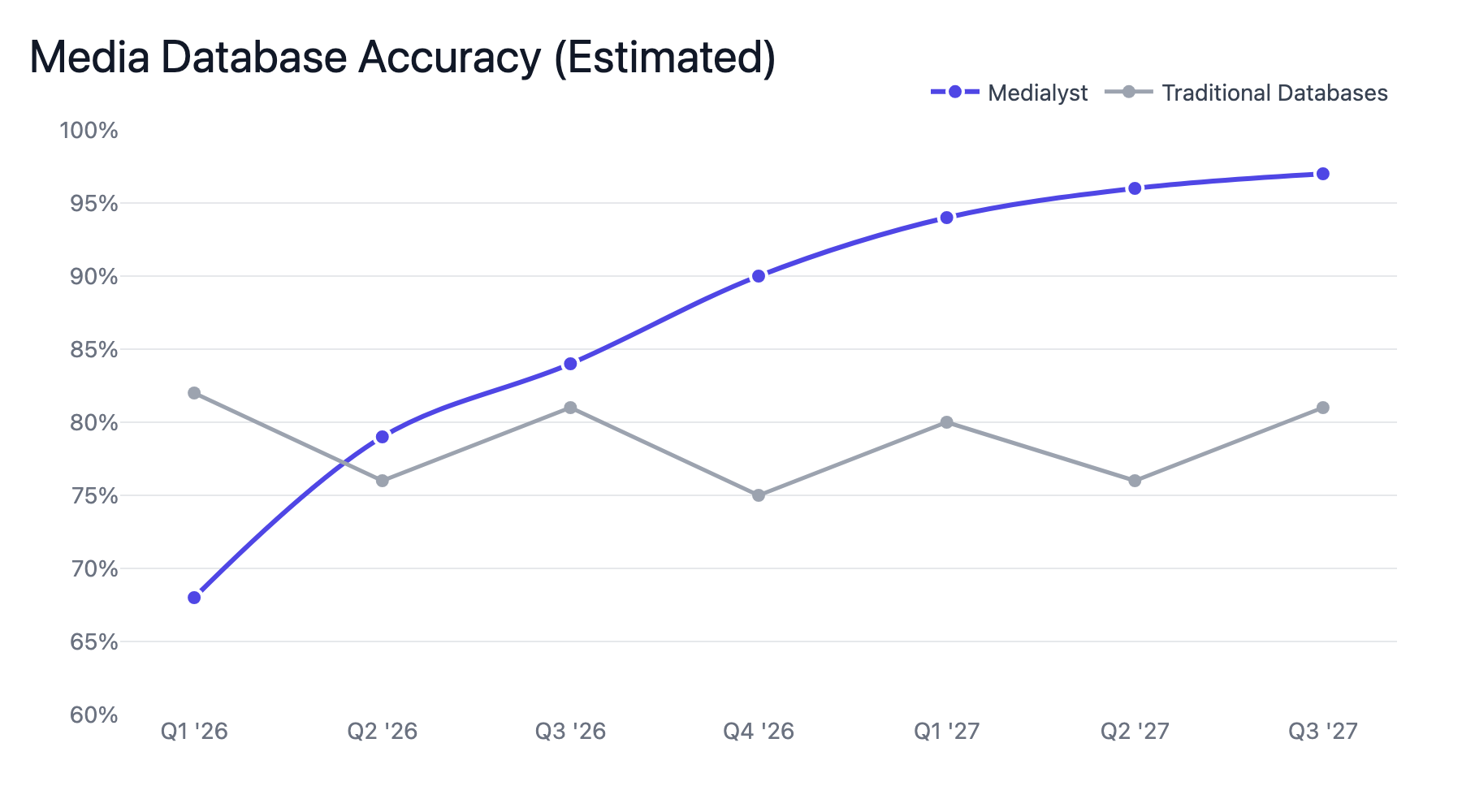
Every query that hits our system—whether served from cache or live-enriched—adds evidence. Every evidence event feeds the AI agents. The agents continuously reconcile, promote, and demote.
The more you use it, the better it gets.
What This Means For You
| When you query... | Traditional DB | Medialyst |
|---|---|---|
| Email accuracy | "Validated Q3 2025" | "Validated 3 days ago" |
| Publication | "Last known: TechCrunch" | "Current: The Information (moved Feb 2026)" |
| Beat | "Technology" | "AI policy, regulation, governance" |
| Confidence | Not shown | Explicit score + source |
| Conflicts | Hidden | Researched and resolved automatically |
| Stale data | Served silently | Live-enriched on the spot |
| Unknown journalist | "Not in database" | Researched and returned in seconds |
The Bottom Line
Traditional media databases are snapshot databases maintained by humans. They're accurate on day 1 of the quarter. By day 90, they're guessing. And when you query a journalist they don't have? Too bad.
Medialyst runs on a living system maintained by AI. Every lookup improves it. Every enrichment teaches it. Every agent decision keeps it fresh. And when data is missing or stale? We enrich it live, right now, using AI agents. You always get fresh data—from the database if we have it, from live enrichment if we don't.
We're not competing on who has more journalists in a spreadsheet. We're competing on who can guarantee that the email you're about to send will actually land.